

「加三嘻行動哇 Yipee! 成為好友」
【Facebook、Youtube、Twitter、Instagram、Telegram、Line】

生成式 AI 模型正在迅速進化,並提供精密性與功能。這項技術進展得以讓各產業的企業與開發人員解決複雜的問題,並發掘新商機。不過生成式 AI 模型的成長,也導致訓練、調整與推論方面的要求變得更加嚴苛。
過去五年來,生成式 AI 模型的參數每年增加十倍,現今的大型模型具有數千億、甚至數兆項參數,即便使用最專門的系統,仍需要相當長的訓練時間,有時需持續數月才能完成。此外,高效率的 AI 工作負載管理需要一個具備一致性、且由最佳化的運算、儲存、網路、軟體和開發框架所組成的整合式 AI 堆疊。
為解決這些難題,Google 推出 Cloud TPU v5p,這是功能最強大、擴充能力最佳,且最具有彈性的 AI 加速器。長久以來,TPU 一直是用來訓練、服務 AI 支援的產品之基礎,這類產品包含 YouTube、Gmail、Google 地圖、Google Play 及 Android。事實上,Google 日前宣布推出的 AI 模型 Gemini 便是使用 TPU 進行訓練與服務。
此外,這次還推出 Google Cloud AI Hypercomputer。AI Hypercomputer 是 Google Cloud 的超級電腦架構,採用整合式系統,並結合了效能最佳化硬體、開放式軟體、領先機器學習架構及靈活彈性的消費模式。傳統上通常是以零碎的方式,在元件層級進行增強以處理要求嚴苛的 AI 工作負載需求,而這可能導致效率不佳,或出現瓶頸。相較之下,AI Hypercomputer 採用系統層級的協同設計來提升 AI 訓練、調整與服務的效率與生產力。
探索 Cloud TPU v5p:Google Cloud 目前功能最強大、擴充能力最佳的 TPU 加速器
Google 在 2023 年 11 月宣布全面推出 Cloud TPU v5e。相較於上一代的 TPU v4,Cloud TPU v5e 的性價比提高了 2.3 倍,是目前最具成本效益的 TPU。而 Cloud TPU v5p 則是目前功能最強大的 TPU。每個 TPU v5p Pod 均由 8,960 個晶片組成,透過頻寬最高的晶片間互連網路(Inter-chip Interconnect, ICI)相連,採用 3D 環面拓撲,提供每晶片 4,800 Gbps 的速度。相較於 TPU v4,TPU v5p 每秒的浮點運算次數(FLOPS)提高 2 倍以上,高頻寬記憶體(High-bandwidth Memory, HBM)則增加 3 倍。
TPU v5p 專為效能、彈性與大規模作業而設計,相較於前一代的 TPU v4,TPU v5p 訓練大型 LLM 模型的速度提升 2.8 倍。不僅如此,若搭配第二代 SparseCores,TPU v5p 訓練嵌入密集模型的速度較 TPU v4 快 1.9 倍。
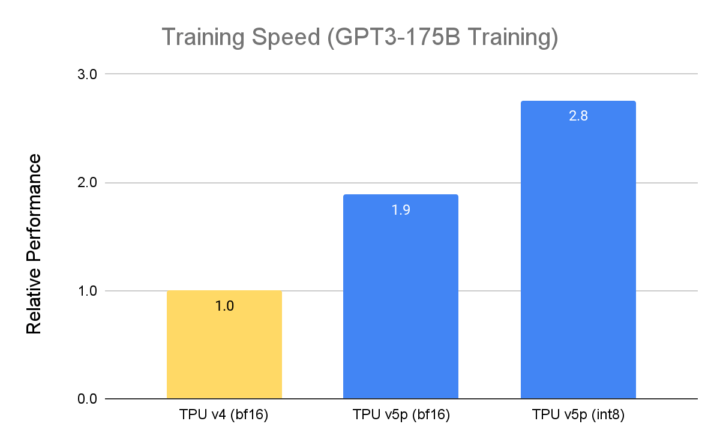
資料來源:Google 內部資料,截至 2023 年 11 月, GPT3-175B的所有數據均以晶片為單位完成標準化作業
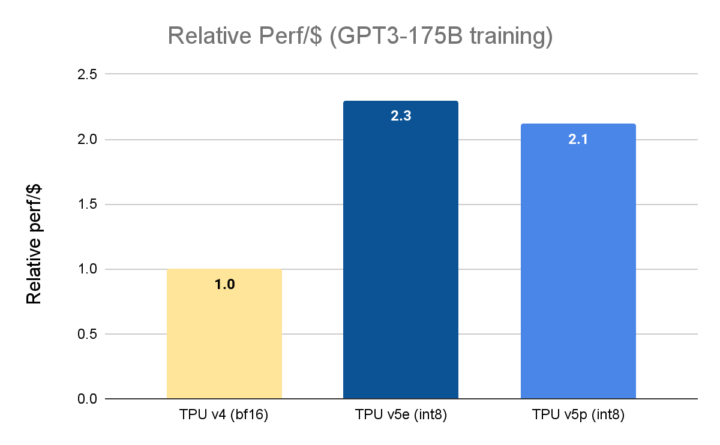
資料來源:TPU v5e 資料來自 MLPerf™ 3.1 Training Closed 的 v5e 結果;TPU v5p 及 v4 數據來自 Google 內部執行的訓練作業。截至 2023 年 11 月,GPT-3 1750 億參數模型的所有數據均以每晶片 seq-len=2048 為單位完成標準化,並以 TPU v4:$3.22 美元/晶片/小時、TPU v5e: $1.2 美元/晶片/小時、以及 TPU v5p:$4.2 美元/晶片/小時的公開定價顯示每美元相對的效能
TPU v5p 不僅效能更優異,就每 Pod 的總可用 FLOPS 而言,TPU v5p 的擴充能力較 TPU v4 高 4 倍,且 TPU v5p 每秒的浮點運算次數(FLOPS)是 TPU v4 的兩倍,並在單一 Pod 中提供兩倍的晶片,可大幅提升訓練速度的相對效能。
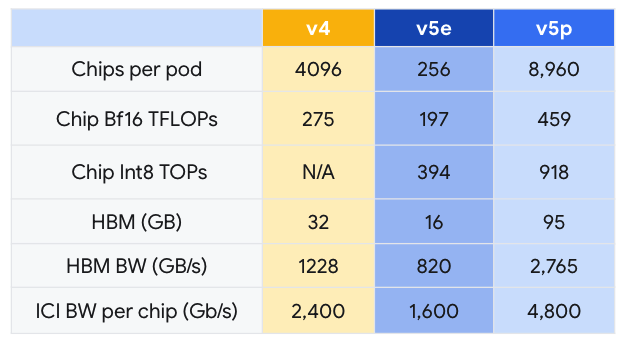
Google AI Hypercomputer 大規模提供頂尖效能與效率
達到規模和速度是必要,但並不足以滿足現代 AI/ML 應用程式與服務的需求。軟硬體元件必須相輔相成,組成一個易於使用、安全可靠的整合式運算系統。Google 已針對此問題投入數十年的時間進行研發,而 AI Hypercomputer 正是我們的心血結晶。此系統集結了多種能協調運作的技術,能以最佳方式來執行現代 AI 工作負載。

- 效能最佳化硬體:AI Hypercomputer 以超大規模資料中心基礎架構為建構基礎,採用高密度足跡、水冷技術以及我們 Jupiter 資料中心網路技術,在運算、儲存與網路功能上皆能提供最佳效能。上述一切均仰賴以效率為核心的技術,不僅採用潔淨能源,並深耕水資源管理,協助我們朝無碳未來邁進。
- 開放式軟體:透過 AI Hypercomputer,開發人員即可使用開放式軟體存取 Google 的效能最佳化硬體,利用這些硬體調整、管理及動態調度管理 AI 訓練與推論的工作負載。
- 廣泛支援多種熱門機器學習架構(例如 JAX、TensorFlow 與 PyTorch),全可立即使用。如要建立複雜的 LLM,JAX 與 PyTorch 均採用 OpenXLA 編譯器。XLA 作為基礎骨幹,提供建立複雜多層式模型的功能 (可參閱 在 Cloud TPU 上使用 PyTorch/XLA 進行 Llama 2 訓練與推論的說明)。XLA 會將廣泛硬體平台的分散式架構調整至最佳狀態,確保各種 AI 用途的模型開發作業既簡單又有效率(可參閱 AssemblyAI 在大規模 AI 語音技術中運用 JAX/XLA 與 Cloud TPU 的說明)。
- 提供開放且獨特的 Multislice Training及Multihost Inferencing 軟體,分別使擴充、訓練與提供模型的工作負載變得流暢又簡單。若要處理需求嚴苛的 AI 工作負載,開發人員可將晶片數量擴充至數萬個。
- 深度整合 Google Kubernetes Engine(GKE) 及 Google Compute Engine,已提供有效率的管理資源、一致的作業環境、自動調度資源、自動佈建節點集區、自動查核點、自動續傳,並即時進行故障復原等作業。
- 靈活彈性的消費模式:AI Hypercomputer 提供廣泛且彈性的動態消費選擇。除了承諾使用折扣(Committed Used Discunts, CUD)、以量計價與現貨價格等傳統選項,AI Hypercomputer 也透過 Dynamic Workload Scheduler 提供專為 AI 工作負載量身打造的消費模式。Dynamic Workload Scheduler 包含兩種消費模式:Flex Start Mode 可取得更多資源,且價格實惠,Calendar Mode 則適用於工作開始時間較容易預測的工作負載。
延伸閱讀:
Google Bard 大升級,即日起將開放 Gemini Pro 模型
AI 模型 Google Gemini 報到!將挑戰 GPT4.0 霸權
Google 旗下 AI 聊天機器人 Bard 升級,可以直接回答 YouTube 影片內容
調查報告顯示 AI 提升釣魚郵件辨識難度,微軟、Google、亞馬遜名列前十大最常遭冒充品牌
Google 推出全新 AI 生成工具,能為廣告主打造個性化廣告
圖片及資料來源:Google
|
|
